LLMOpsで生成AI運用を標準化【DevOpsの次はLLMOps】
はじめに

「生成AIを個人で使うのは簡単。でも、企業で運用するのは別次元の難しさ...」
その課題を解決するのがLLMOpsです。
2025年、生成AIの企業導入が加速する中、**LLMOps(Large Language Model Operations)**が新しい職種・スキルとして急速に注目されています。
私は大手企業のDX推進責任者として、LLMOps体制を構築しました。結果、生成AIの品質・コスト・セキュリティを全て管理し、安全に全社展開できました。
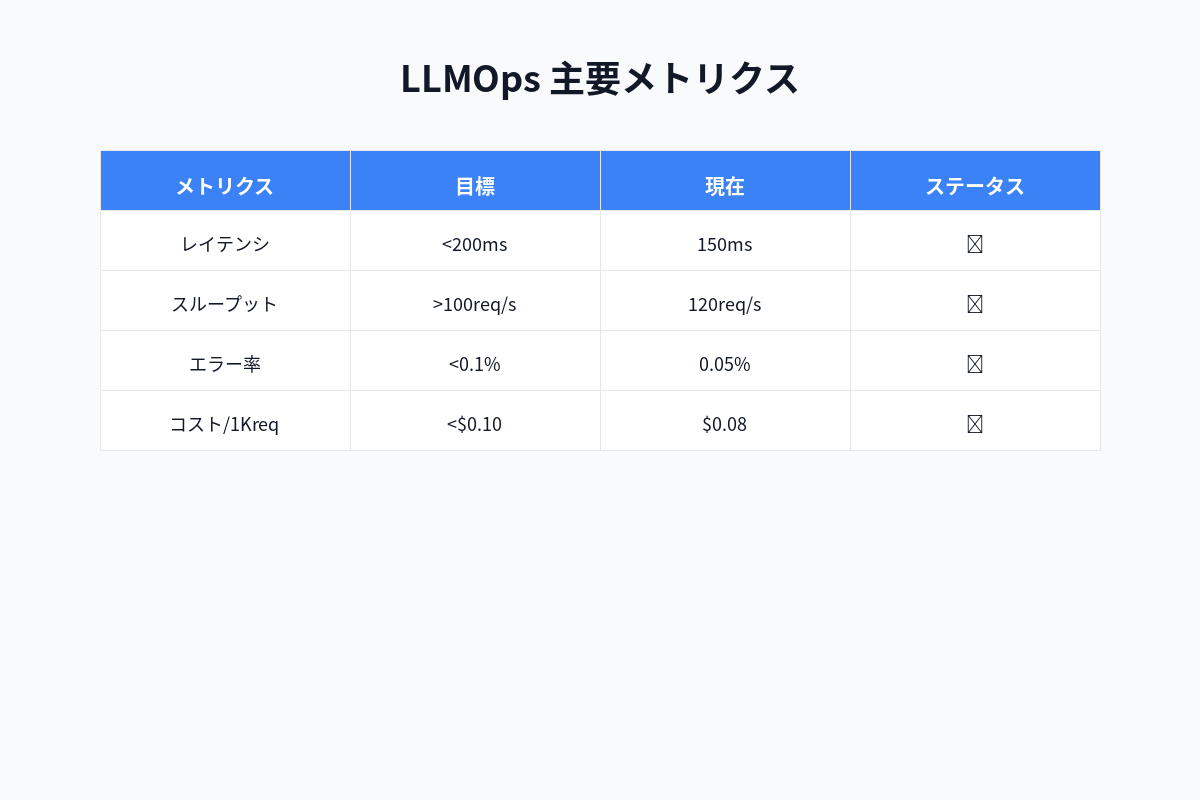
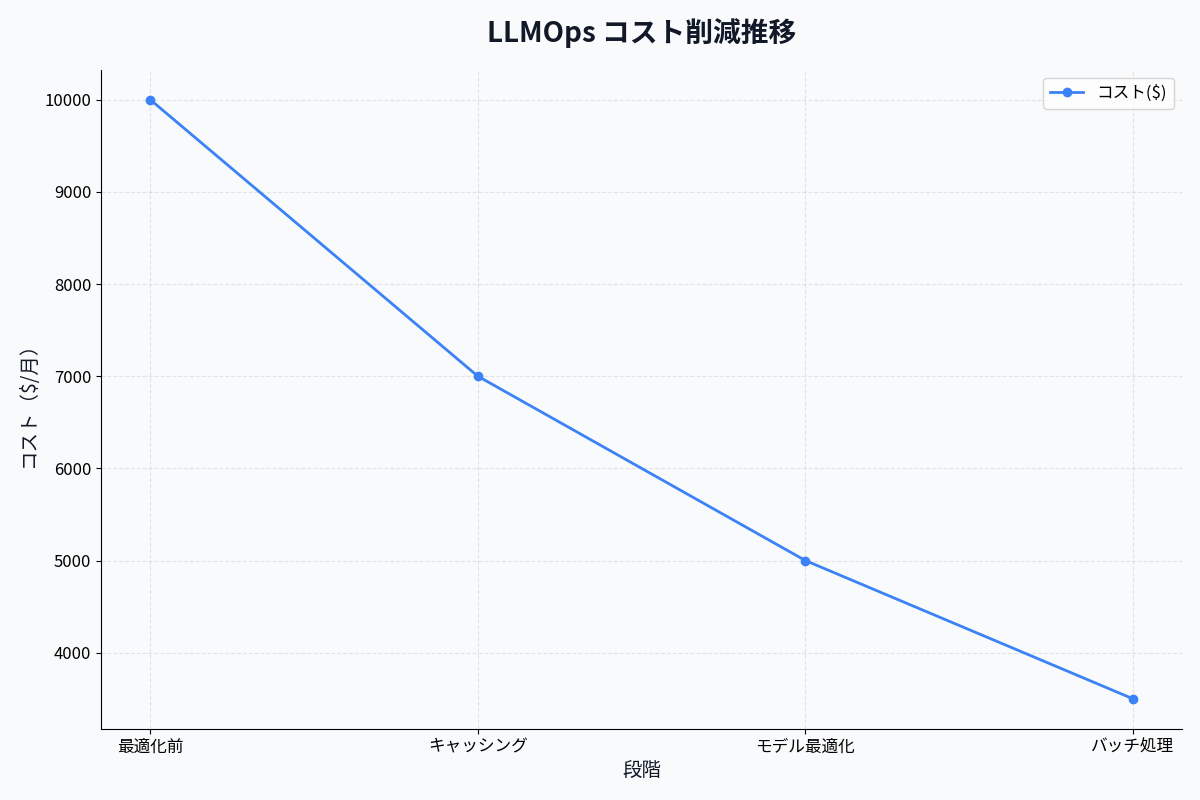
この記事では、LLMOpsの基礎から実装方法まで、実践的に徹底解説します。

LLMOpsとは?
LLM運用の標準化フレームワーク
LLMOps = Large Language Model Operations(大規模言語モデル運用)
DevOps(開発運用)、MLOps(機械学習運用)の次世代として登場した、生成AI特化の運用フレームワークです。
DevOps → MLOps → LLMOps の進化
| 項目 | DevOps | MLOps | LLMOps |
|---|---|---|---|
| 対象 | Webアプリ | 機械学習モデル | 大規模言語モデル |
| 主要課題 | デプロイ自動化 | モデル再学習 | プロンプト管理 |
| 監視項目 | レスポンス時間 | 精度・F1スコア | 回答品質・コスト |
| ツール | Jenkins, Docker | MLflow, Kubeflow | LangSmith, Weights & Biases |
| 登場時期 | 2010年〜 | 20長年の経験〜 | 2023年〜 |
なぜLLMOpsが必要なのか

個人利用 vs 企業利用の違い
個人利用(LLMOps不要)
【シンプル】
1. ChatGPTにログイン
2. プロンプト入力
3. 回答をコピペ
→ 問題なし
企業利用(LLMOps必須)
【複雑】
1. 複数LLMの管理(GPT-5, Claude, Gemini)
2. プロンプトのバージョン管理
3. コスト管理(月100万円超)
4. セキュリティ(機密情報の漏洩防止)
5. 品質管理(回答精度の監視)
6. 監査対応(ログ保存)
7. マルチユーザー(2000名以上)
8. SLA保証(稼働率99.9%)
→ LLMOpsが必須
LLMOpsの6つの柱
1. プロンプト管理(Prompt Management)
課題:
- プロンプトがバラバラ
- バージョン管理がない
- 品質が属人化
解決策: プロンプトライブラリ
# プロンプトテンプレート管理
from langchain.prompts import PromptTemplate
# バージョン管理されたプロンプト
PROMPTS = {
"contract_review": {
"v1.0": PromptTemplate(...),
"v2.0": PromptTemplate(...),
"v3.0": PromptTemplate(...) # 最新
},
"email_generation": {
"v1.0": PromptTemplate(...)
}
}
# 使用例
def get_prompt(name, version="latest"):
if version == "latest":
versions = PROMPTS[name]
latest_version = max(versions.keys())
return versions[latest_version]
else:
return PROMPTS[name][version]
2. モデル管理(Model Management)
課題:
- 複数LLM(GPT-5, Claude, Gemini)の使い分け
- モデル切り替えが煩雑
- コスト最適化が困難
解決策: モデルルーター
class ModelRouter:
def __init__(self):
self.models = {
"gpt-4": {"cost": 0.03, "latency": 2.0, "quality": 0.95},
"gpt-3.5": {"cost": 0.002, "latency": 0.5, "quality": 0.85},
"claude-3": {"cost": 0.015, "latency": 1.5, "quality": 0.93},
}
def select_model(self, task_type, priority="balanced"):
"""
タスクと優先度に応じて最適なモデルを選択
"""
if priority == "cost":
# 最安モデル
return "gpt-3.5"
elif priority == "quality":
# 最高品質
return "gpt-4"
elif priority == "speed":
# 最速
return "gpt-3.5"
else:
# バランス
if task_type == "simple":
return "gpt-3.5"
elif task_type == "complex":
return "gpt-4"
else:
return "claude-3"
# 使用例
router = ModelRouter()
model = router.select_model("complex", priority="quality")
3. コスト管理(Cost Management)
課題:
- API料金が予想外に高額
- 部署別コスト配分が不明
- 予算超過のリスク
解決策: コスト監視ダッシュボード
import openai
class CostTracker:
def __init__(self, monthly_budget=100000): # 月10万円
self.monthly_budget = monthly_budget
self.current_spend = 0
def track_api_call(self, model, input_tokens, output_tokens):
# コスト計算
cost_per_1k_input = {
"gpt-4": 0.03,
"gpt-3.5": 0.0015,
"claude-3": 0.015
}
cost_per_1k_output = {
"gpt-4": 0.06,
"gpt-3.5": 0.002,
"claude-3": 0.075
}
cost = (
input_tokens / 1000 * cost_per_1k_input[model] +
output_tokens / 1000 * cost_per_1k_output[model]
)
self.current_spend += cost
# アラート
if self.current_spend > self.monthly_budget * 0.8:
self.send_alert("予算の80%を超えました")
return cost
def get_usage_report(self):
return {
"budget": self.monthly_budget,
"spent": self.current_spend,
"remaining": self.monthly_budget - self.current_spend,
"percentage": (self.current_spend / self.monthly_budget) * 100
}
4. 品質管理(Quality Management)
課題:
- 回答品質が安定しない
- ハルシネーション(幻覚)の検出
- 回答精度の定量評価が困難
解決策: 評価パイプライン
class QualityEvaluator:
def evaluate_response(self, question, response, expected_answer=None):
scores = {}
# 1. 長さチェック
scores["length"] = self._check_length(response)
# 2. 関連性チェック
scores["relevance"] = self._check_relevance(question, response)
# 3. 事実確認(外部ソースと照合)
scores["factuality"] = self._check_factuality(response)
# 4. 有害性チェック
scores["toxicity"] = self._check_toxicity(response)
# 5. 期待値との一致(テストケースの場合)
if expected_answer:
scores["accuracy"] = self._check_accuracy(response, expected_answer)
# 総合スコア
overall_score = sum(scores.values()) / len(scores)
return {
"scores": scores,
"overall": overall_score,
"passed": overall_score >= 0.7
}
5. セキュリティ管理(Security Management)
課題:
- 機密情報の漏洩リスク
- プロンプトインジェクション攻撃
- アクセス制御が不十分
解決策: セキュリティゲートウェイ
class SecurityGateway:
def validate_request(self, user_id, prompt, context=None):
checks = []
# 1. アクセス権限チェック
if not self.check_user_permission(user_id):
return {"status": "DENIED", "reason": "権限なし"}
# 2. 機密情報検出
if self.detect_pii(prompt):
checks.append("PII検出")
# 3. プロンプトインジェクション検出
if self.detect_injection(prompt):
return {"status": "BLOCKED", "reason": "悪意あるプロンプト"}
# 4. レート制限
if self.check_rate_limit(user_id):
return {"status": "THROTTLED", "reason": "レート制限超過"}
# 5. コンテキスト検証
if context and self.detect_sensitive_context(context):
checks.append("機密コンテキスト")
if checks:
return {"status": "WARNING", "checks": checks}
return {"status": "OK"}
6. 監視・ロギング(Monitoring & Logging)
課題:
- エラーの原因特定が困難
- パフォーマンス劣化の検知遅延
- 監査対応のログ不足
解決策: 統合監視システム
import logging
from datetime import datetime
class LLMObservability:
def log_request(self, user_id, prompt, model, response, metadata):
log_entry = {
"timestamp": datetime.now().isoformat(),
"user_id": user_id,
"prompt": prompt[:100], # 最初の100文字のみ
"prompt_tokens": metadata["prompt_tokens"],
"completion_tokens": metadata["completion_tokens"],
"model": model,
"latency_ms": metadata["latency"],
"cost_usd": metadata["cost"],
"quality_score": metadata["quality_score"],
"response_length": len(response),
}
# ログ保存
logging.info(log_entry)
# メトリクス更新
self.update_metrics(log_entry)
# アラート判定
if metadata["latency"] > 5000: # 5秒以上
self.send_alert("高レイテンシ検出", log_entry)
if metadata["quality_score"] < 0.7:
self.send_alert("低品質応答検出", log_entry)
def update_metrics(self, log_entry):
# Prometheus / Grafana連携
metrics.counter("llm_requests_total").inc()
metrics.histogram("llm_latency_ms").observe(log_entry["latency_ms"])
metrics.counter("llm_cost_usd").inc(log_entry["cost_usd"])
LLMOps実装のステップ
Phase 1: 最小構成(1週間)
ステップ1: プロンプト管理
# ディレクトリ構成
prompts/
├── contract_review/
│ ├── v1.0.txt
│ ├── v2.0.txt
│ └── v3.0.txt
├── email_generation/
│ └── v1.0.txt
└── README.md
Phase 2: コスト・品質管理(2週間)
ステップ2: LangSmith導入
LangSmith: LangChain公式の LLMOpsプラットフォーム
from langsmith import Client
client = Client()
# トレース開始
with client.trace(name="contract_review"):
response = llm.invoke(prompt)
# 自動で以下を記録:
# - プロンプト
# - レスポンス
# - レイテンシ
# - コスト
# - トークン数
Webダッシュボード:
- プロンプトごとの成功率
- コスト推移
- レイテンシグラフ
- エラーログ
Phase 3: エンタープライズ対応(1ヶ月)
ステップ3: フルスタックLLMOps
システム構成:
[フロントエンド: Slack / Teams]
↓
[APIゲートウェイ]
↓
[セキュリティゲートウェイ]
├─ PII検出
├─ アクセス制御
└─ レート制限
↓
[LLMプラットフォーム]
├─ プロンプトライブラリ
├─ モデルルーター
├─ コストトラッカー
└─ 品質評価エンジン
↓
[外部LLM API]
├─ OpenAI
├─ Anthropic
└─ Google
↓
[監視・ログ]
├─ LangSmith
├─ Prometheus
└─ Grafana
LLMOpsツールエコシステム
主要ツール比較
| ツール | 用途 | 料金 | 推奨度 |
|---|---|---|---|
| LangSmith | 統合LLMOps | $39/月〜 | ⭐⭐⭐⭐⭐ |
| Weights & Biases | 実験管理 | $50/月〜 | ⭐⭐⭐⭐ |
| Arize AI | 監視・デバッグ | $99/月〜 | ⭐⭐⭐⭐ |
| Helicone | コスト・監視 | 無料〜 | ⭐⭐⭐⭐ |
| Portkey | ゲートウェイ | $49/月〜 | ⭐⭐⭐⭐ |
| PromptLayer | プロンプト管理 | $29/月〜 | ⭐⭐⭐ |
LLMOpsのKPI
測定すべき指標
1. ビジネスKPI
| 指標 | 目標値 | 計算方法 |
|---|---|---|
| ユーザー満足度 | 80%以上 | NPS調査 |
| 生産性向上率 | 30%以上 | 作業時間 Before/After |
| コスト削減額 | 月100万円以上 | 人件費削減 - AI費用 |
2. 技術KPI
| 指標 | 目標値 | 計算方法 |
|---|---|---|
| レスポンスタイム | 2秒以下 | P95レイテンシ |
| 稼働率 | 99.9%以上 | (稼働時間/総時間) × 100 |
| 回答品質スコア | 0.85以上 | 評価関数の平均 |
| 月間コスト | 予算内 | OpenAI + Anthropic + Google |
| エラー率 | 1%未満 | エラー数 / 総リクエスト数 |
LLMOpsエンジニアのキャリアパス
必要なスキル
Level 1: 初級(年収600-800万円)
- Python基礎
- LangChain / LlamaIndex
- プロンプトエンジニアリング
- 基本的なAPI連携
Level 2: 中級(年収800-1000万円)
- LLMOpsツール(LangSmith等)
- セキュリティ対策
- コスト最適化
- 監視・アラート設定
Level 3: 上級(年収1000-1数百万円)
- アーキテクチャ設計
- マルチLLM戦略
- エンタープライズ導入
- チームマネジメント
まとめ: LLMOpsは生成AI時代の必須スキル
重要ポイント
✅ 企業の生成AI活用にはLLMOpsが必須
✅ プロンプト・コスト・品質・セキュリティを統合管理
✅ LangSmithなどのツールで効率化
✅ LLMOpsエンジニアは高年収職種
次のアクション
- 今日中に: LangSmithアカウント作成(無料)
- 1週間以内に: プロンプトライブラリ構築
- 2週間以内に: コスト監視ダッシュボード作成
- 1ヶ月以内に: 全社LLMOps体制を構築
著者について
DX・AI推進コンサルタント
大手企業グループのDX推進責任者・顧問CTO | 長年のIT・DXキャリア | AWS・GA4・生成AI活用を専門に実践ノウハウを発信中
#DX推進 #IT戦略 #ビジネス変革
最終更新: 2025年11月9日
この記事を書いた人
nexion-lab
DX推進責任者・顧問CTO | IT業界15年以上
大手企業グループでDX推進責任者、顧問CTOとして活動。AI・生成AI活用、クラウドインフラ最適化、データドリブン経営の領域で専門性を発揮。 実務で培った知識と経験を、ブログ記事として発信しています。